
Введение в аннотацию (так называемая маркировка).
ИИ на основе изображений обучаются с использованием помеченных данных. Это также называется «наземной правдой», «помеченными» или «аннотированными» данными. Существует несколько типов «аннотаций» для различных моделей данных. Они различаются и включают в себя такие вещи, как аннотация «ключевой точки», «интерполяция», «оценка позы» и так далее. В этой статье мы сосредоточимся на четырех наиболее часто используемых типах аннотаций:
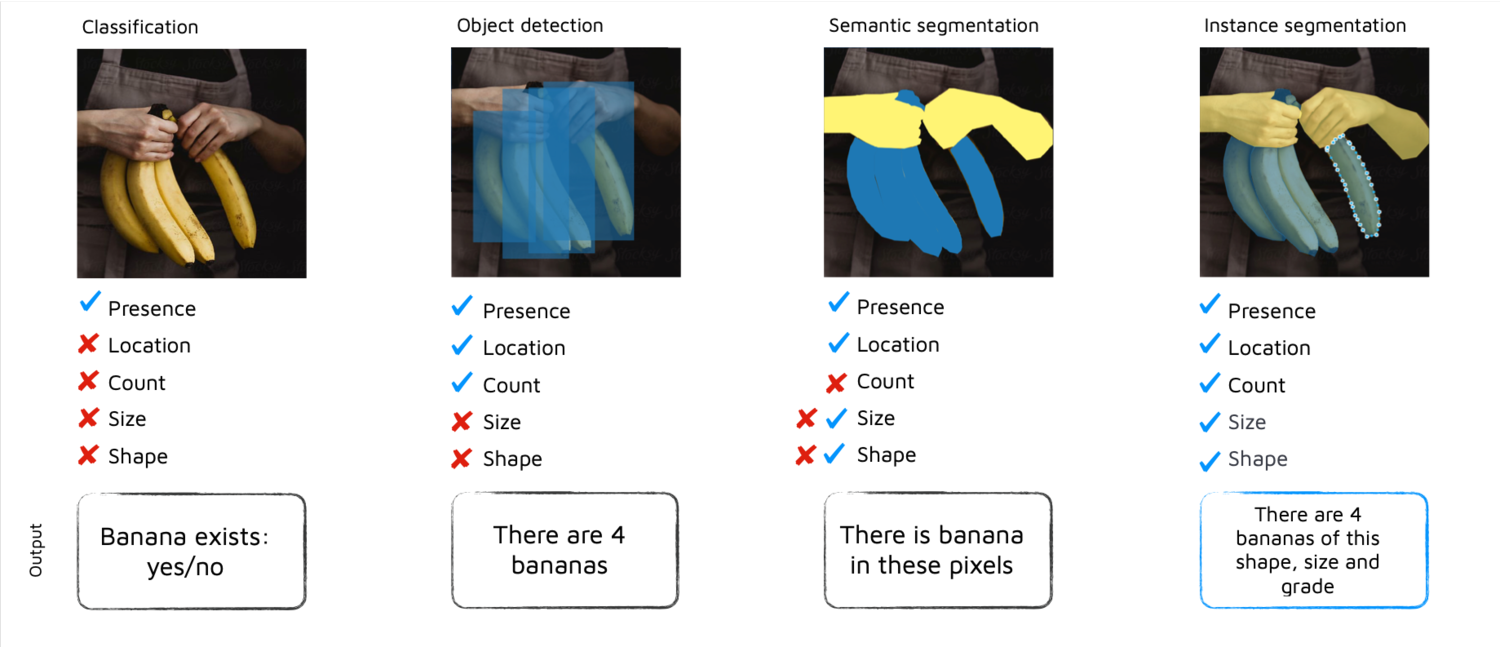
- Классификация (часто называемая тегами).Это полезно для быстрой индикации атрибутов изображения. Он включает в себя наличие объекта, настроения или фона на изображении. Это самая простая форма аннотации и та, которую мы видим в таких вещах, как Google-капча. Тем не менее, функциональность ограничена, так как положение, форма и уникальные атрибуты объектов неизвестны, и для надежного изучения этих деталей с помощью этого метода потребуется аннотировать миллионы изображений.
- Обнаружение объектов (так называемые ограничивающие рамки)Это полезно для определения местоположения отдельных объектов на изображении. Аннотация относительно проста, так как нужно просто нарисовать плотную рамку вокруг намеченного объекта. Преимущества здесь в том, что хранение этой информации и необходимые вычисления относительно легки. Недостатком является то, что «шум» в рамке - захваченный «фон» - часто мешает модели изучать форму и размер объекта. Таким образом, этот метод сталкивается с трудностями, когда существует высокий уровень «окклюзии» (перекрывающиеся или препятствующие объекты) или высокая дисперсия в форме объекта, и эта информация важна - подумайте о типах биологических клеток или платьев.Обнаружение объекта - «шум» - это песок, включенный в ограничивающую рамку.
- Семантическая сегментация полезна для указания формы чего-либо, где счет не имеет значения, такого как небо, дорога или просто фон. Преимущества здесь в том, что при добавлении аннотации к каждому пикселю на всем изображении появляется намного больше информации. Ваша цель - точно знать, где находятся регионы и их форма. Проблема с этим методом состоит в том, что каждый пиксель должен быть аннотирован, а процесс занимает много времени и подвержен ошибкам.
- Сегментация экземпляров полезна для обозначения отдельных объектов, таких как автомобиль 1, автомобиль 2, цветок a, цветок b или привод. Преимущества состоят в том, что формы и атрибуты объектов изучаются гораздо быстрее, что требует меньше примеров, а окклюзии обрабатываются намного лучше, чем при обнаружении объектов. Проблема в том, что этот метод требует очень много времени и подвержен ошибкам.
Проблемы сегментации: Как вы можете видеть, сегментация и семантическая сегментация занимают много времени, так как необходимо вручную очертить точный целевой объект - точку за точкой с «многоугольником» или даже пиксель за пикселем с «маской». Вот почему он так подвержен ошибкам. На самом деле, лучшие аннотаторы в мире имеют 4–6% ошибок, в то время как средний человек имеет около 8–9%. Этот коэффициент ошибок существенно влияет на производительность конечного ИИ и часто является тем, что мешает проектам сделать это через этап проверки концепции.Теперь представьте, что целевые объекты являются сложными, такими как органические клетки или механические предметы. Кроме того, что если допустимый предел погрешности невелик, поскольку последствия неправильного решения модели могут быть ужасными или даже фатальными. Обычно в этих нетривиальных случаях сегментация наиболее полезна и необходима для достижения высокопроизводительной модели.70% работ, необходимых для создания искусственного интеллекта на основе изображений, составляют аннотации.
Если вы видите, что ИИ работает на практике (например, автономное вождение), то знайте, что людям потребовались миллионы часов для создания достаточного количества маркированных данных, чтобы обучить эту нейронную сеть до такой степени, чтобы команда чувствовала себя достаточно уверенно, чтобы запустить ее в производство. Даже в этом случае чаще всего возникает необходимость в перемаркировке или маркировке дополнительных данных после развертывания модели.
Преимущество в автоматизации этой ручной работы является наибольшим, когда для аннотирования этих изображений необходимы эксперты. Типичные случаи использования включают медицинскую и биологическую визуализацию, робототехнику, обеспечение качества, современные материалы и сельское хозяйство.
Цель автоматизации в машинном зрении состоит в том, чтобы определить контур объекта, предоставляя как можно меньше входных данных. В этом разделе мы в основном будем ссылаться на автоматизацию задач сегментации, поскольку это, как правило, наиболее трудоемко.Уровни автоматизации в этом контексте могут быть обозначены как оценка структуры:
- Уровень 1: один объект на одном изображении
- Уровень 2: несколько объектов в одном изображении
- Уровень 3: оценка контура нескольких объектов на нескольких изображениях
Цель состоит в том, чтобы точно оценить контур всех объектов на всех изображениях для данного проекта.
Уровень 1 - аннотировать объект в считанные секундыИспользование классических методов компьютерного зрения, распространенных из хорошо известной платформы OpenCV, инструменты, известные из Photoshop, и даже некоторые из них, основанные на новых подходах к искусственному интеллекту, являются инструментами, которые стремятся максимально автоматизировать аннотацию одного объекта. Примеры инструментов уровня 1 включают в себя:Контур | смотрит на контуры на основе контрастов> отлично подходит для объектов на контрастном фонеGrabCut | извлекает фон из переднего плана для заданной области> отлично подходит для объектов на монохроматическом фонеВолшебная палочка | выбирает область, находя похожие пиксели рядом с выбранным пикселем для заданного диапазона> отлично подходит для монохроматических (или близких) объектовDEXTR | использует модель, обученную на большом общем наборе данных, чтобы попытаться определить контур объекта в пределах определенной области> отлично подходит для динамических объектов на динамическом фоне DEXTR - пометить полное изображение за считанные минуты

ПРИМЕЧАНИЕ: часто инструменты аннотации требуют «автоматической маркировки» с такими функциями, как DEXTR. Тем не менее, это по-прежнему ручной инструмент, основанный на предварительном обучении общим наборам данных, который дает рекомендации по каждому объекту. Не поймите нас неправильно, этот инструмент великолепен и может использоваться для достижения уровня 1 автоматизации, но он далек от полной «автоматической маркировки».
Уровень 2 - аннотировать полное изображение в считанные секундыНа этом уровне вы пытаетесь аннотировать все объекты на изображении одним действием. Это близко к современному уровню глубокого обучения. Экономия времени по сравнению с уровнем 1 является радикальной, так как человеческий вклад радикально уменьшается. Однако эта автоматизация требует более высокого уровня достоверности, чем уровень 1. Это означает, что проект аннотации запускается с использованием инструментов уровня 1, пока инструменты уровня 2 не будут готовы к развертыванию.Instance segmentation assistant - пометьте полное изображение за несколько секундУровень 2 автоматизация достигается с использованием помощников AI. Эти помощники учатся в фоновом режиме, пока вы комментируете. Когда они достигли определенного доверительного уровня, вы, как пользователь, можете начать использовать их и получать предложения не только для отдельных объектов, но и для полного изображения. Помощник переобучается и совершенствуется по мере создания новых изображений.
Уровень 3 - аннотировать полный пакет изображений / проект в считанные секунды. Когда аннотации были автоматизированы до этого уровня, вы как пользователь должны иметь возможность комментировать коллекцию изображений или даже полный проект в считанные секунды. Здесь ожидается, что вы, как пользователь, просто нажимаете кнопку, и все изображения в проекте снабжаются комментариями.Завершить весь набор данных в считанные секунды ...Хотя инструменты уровня 3 чрезвычайно эффективны, они также сопряжены с трудностями. Например, если вы аннотируете набор данных, содержащий 10 000 изображений животных, 1 000 из которых уже были аннотированы, а инструменту уровня 3 трудно отличить лягушек от жаб, то 9 000 изображений, которые вы автоматически аннотируете с помощью этого инструмента, могут иметь серьезные проблемы с качеством. То, что должно быть классифицировано как лягушки, теперь является жабой, и наоборот, сделанные примечания непригодны для использования. Это ошибка классификации - только один из четырех типов ошибок, которые могут возникнуть. Остальные генерируют артефакты, неточные сегменты или вообще пропускают объекты.Таким образом, чтобы использовать инструмент уровня 3, вы должны быть очень уверены, что результаты будут точными и процент ошибок будет очень низким (<0,5%). Эта определенность может быть достигнута, если принять во внимание поведение пользователя для уровня автоматизации 2, например, внести незначительные изменения или вообще не вносить изменения в предложения уровня 2 и посмотреть на такие вещи, как уровни доверия.
По данным источника: https://hackernoon.com/